Feature #274
openCODA 3 data format
Description
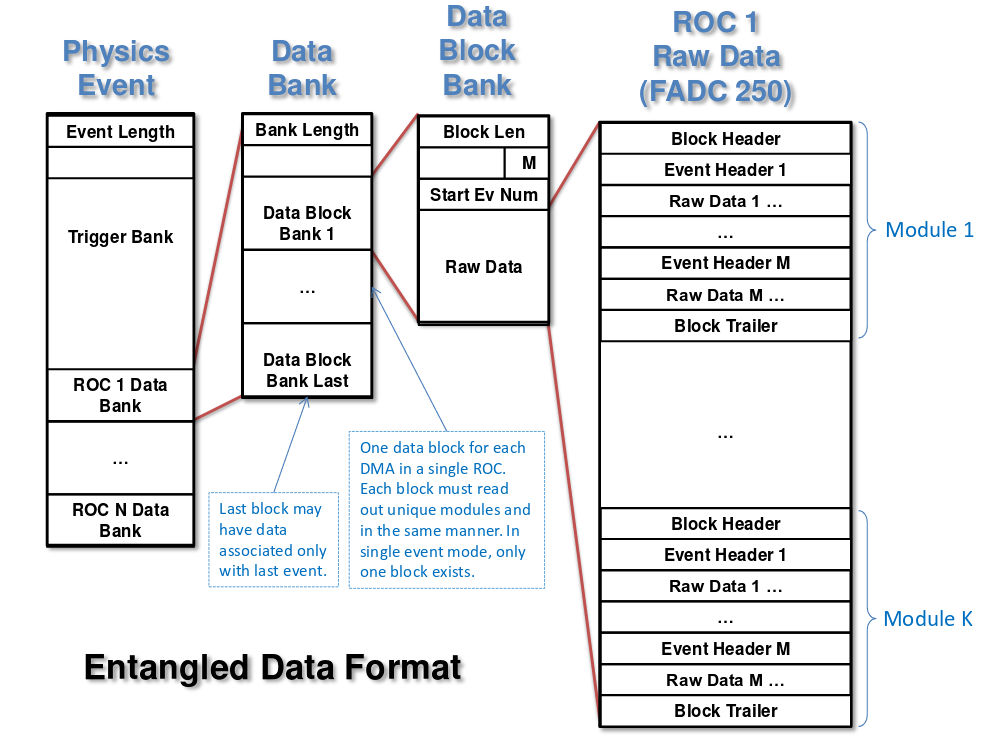
Attached is a short version summary of the CODA 3 data format. It is very different from CODA 2.6.2. So we'll need an alternative version of some parts of the decoder for that. I have some example code from the DAQ group.
So, my task is to implement that privately so that my test-stand data can be analyzed, then use data to test the solution to the parent issue (static variable in Pipelining...) and submit that solution (only) for now. The CODA 3 format can wait a bit.
Files
{kind=link}
Related issues
Updated by Ole Hansen about 8 years ago
- Tracker changed from Task to Feature
- Status changed from New to In Progress
- Assignee set to Robert Michaels
- Target version set to 1.7
- % Done changed from 0 to 20
- Estimated time set to 40.00 h
- Parent task deleted (
#265)
Updated by Ole Hansen about 8 years ago
- Related to Bug #265: Static variable in PipeliningModule::SplitBuffer added
Updated by Robert Michaels about 8 years ago
In the EVIO library there is a function called evIoctl, which returns the version of EVIO that was used to write the data file. All CODA 3.* files are written with EVIO version 4, and all CODA 2.* used lower EVIO versions. The differences in the files is only in the "infrastructure" for discovering what the event type, event number, the pointers to the crates, and a few general things like that. Once you unpack the crates and start to crawl through their data words, the decoding is the same for all versions of CODA. So, the task is to detect the EVIO version, use that to define the CODA version, then tell CodaDecoder to either use the old "infrastructure" decoding or the new one. I've obtained a working example of the new one from the DAQ group. I think I can finish this job in a week or two, including testing.
Updated by Robert Michaels about 8 years ago
- % Done changed from 20 to 60
It looks like this job is mostly done. The version of CODA is automatically detected. For the old version 2.* the decoding is identical. It was compared to the results of the Master Branch, and I did the usual "all histograms identical" test on some data. For the new version 3.* I took some data with different block levels and different modes for the FADC, and unfortunately I hit a snag that the following condition is never met: (data_type_def==1 && data_type_def==0), hence I don't find block headers, slot numbers or how many events in a block. I do see event headers, though. Basically, I am lost and will need to ask the DAQ group for some advice.
Updated by Robert Michaels about 8 years ago
- % Done changed from 60 to 100
- Estimated time changed from 40.00 h to 50.00 h
I fixed the aforementioned problems -- it was a DAQ problem. But it was a good thing because now I have some redundant checks. The number of blocks is recorded in each module in their bank header (which was being erroneously discarded by the DAQ due to a configuration problem), but also in the trigger bank info that comes with CODA3. These are cross-checked now. All checks finished and ready for a pull request.